read.table()Lee archivos y los esquematiza en una tabla
sample()Genera números aleatorios
4.1.2 Medidas de tendencia central
mean()Media
median()Mediana
quantile()Cuartiles/percentiles
4.1.3 Medidas de dispersión
sd()Desviación estándar
var()Varianza
IQR()Rango intercuartílico
range()Rango total
fivenum()Mínimo, primer cuartil, mediana, tercer cuartil y máximo
4.1.4 Distribuciones
dnorm()Densidad normal
ppois()Probabilidad acumulada Poisson
rbinom()Generador binomial
`
4.1.5 Pruebas de hipótesis
t.test()T-Student
cor.test()Correlación
chisq.test()Chi-cuadrado
aov()ANOVA
4.1.6 Modelización
lm()Regresión lineal
glm()Modelos lineales generalizados
nls()Mínimos cuadrados no lineales
4.1.7 Gráficos
boxplot()Diagrama de caja y bigotes
hist()Histograma
4.2 Diseño muestral
Se sabe que el consumo de alcohol durante el embarazo puede dañar al feto. Para estudiar este fenómeno, se asignarán 20 ratones preñados a tres grupos de tratamiento. El grupo 1 (diez ratones) no recibirá alcohol y el grupo 2 (cinco ratones) recibirá una dosis elevada. Prepara una asignación completamente aleatoria. Use R para etiquetar y aleatorizar.
Colocar un set.seed() para que la aleatorización no se realiza cada vez que se ejecuta el código
individuos tratamientos
1 16 control
2 8 control
3 9 control
6 7 control
7 18 control
8 2 control
9 20 control
10 3 control
15 4 control
17 19 control
4 15 dosis alta
16 11 dosis alta
18 6 dosis alta
19 17 dosis alta
20 1 dosis alta
5 12 dosis media
11 10 dosis media
12 5 dosis media
13 13 dosis media
14 14 dosis media
4.3 Analisis de varianza ANOVA
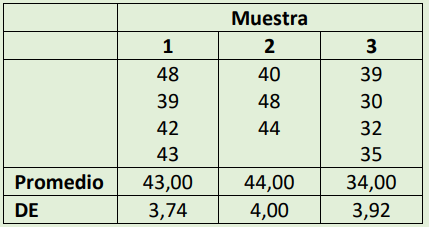
los datos de la tabla lo planteamos en forma de codigo, son tres columnas (3 muestras), la primera tiene 4 datos, la segunda tiene 3, y la tercera 4
Para resolverlo primero llamamos a library(car) para usar la función leveneTest(), crearemos un objeto (data1) donde crearemos nuestro data frame. La función factor() para generar variables explicativas continuas y las repeticiones que tendrán por grupo, el cual se asignará con otro vector
$`1`
Shapiro-Wilk normality test
data: X[[i]]
W = 0.96058, p-value = 0.7825
$`2`
Shapiro-Wilk normality test
data: X[[i]]
W = 1, p-value = 1
$`3`
Shapiro-Wilk normality test
data: X[[i]]
W = 0.97133, p-value = 0.8497
los valores de la prueba shapiro tienen un P>0.05 por lo tanto no rechazan hipótesis nula.
prueba de homocedasticidad
#el simbolo "~" se hace con "Ctrl + Alt + +"leveneTest(medidas ~ muestras, data = data1)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 0.0519 0.9497
8
la prueba no rechaza la hipotesis nula, por lo tanto si hay homocedasticidad y podemos proceder con el analisis conveniente: en este caso ANOVA de un factor.
Prueba ANOVA
#primero creamos un modelo y luego la función anova hacia ese modelo#"~" se hace con "Ctrl + Alt + +"modelo1 <-lm(medidas ~ muestras, data = data1)modelo1
Analysis of Variance Table
Response: medidas
Df Sum Sq Mean Sq F value Pr(>F)
muestras 2 228 114 7.6 0.01414 *
Residuals 8 120 15
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
el anova indica diferencia significativa de las medias de los grupos debido a que P=0.014 < 0.05
como prueba Post-hoc realizaremos la prueba Tukey
#primero cambiaremos la estructura del objeto "modelo1"anova1 <-aov(modelo1)anova1
Call:
aov(formula = modelo1)
Terms:
muestras Residuals
Sum of Squares 228 120
Deg. of Freedom 2 8
Residual standard error: 3.872983
Estimated effects may be unbalanced
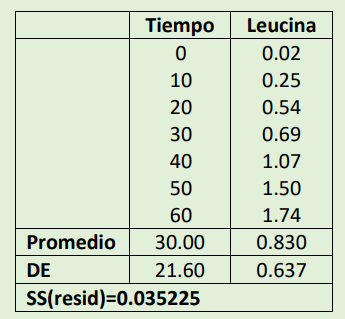
Ejercicio: En un estudio sobre la síntesis de proteínas en el ovocito (célula huevo en desarrollo) de la rana Xenopus laevis, un biólogo inyectó leucina radiactiva en ovocitos individuales. En distintos momentos tras la inyección, realizó mediciones de radiactividad y calculó la cantidad de leucinaque se había incorporado a la proteína. Los resultados se muestran en la tabla adjunta; cada valor de leucina es el contenido de leucina marcada en dos ovocitos. Todos los ovocitos procedían de la misma hembra.
modelo2 <-lm(leucina ~ tiempo, data = data2)modelo2
Call:
lm(formula = leucina ~ tiempo, data = data2)
Coefficients:
(Intercept) tiempo
-0.04750 0.02925
se observa el intercepto: -0.048 y el coeficiente de x: 0.029 siendo el modelo: y=0.029x - 0.048 (y:leucina; x:tiempo)
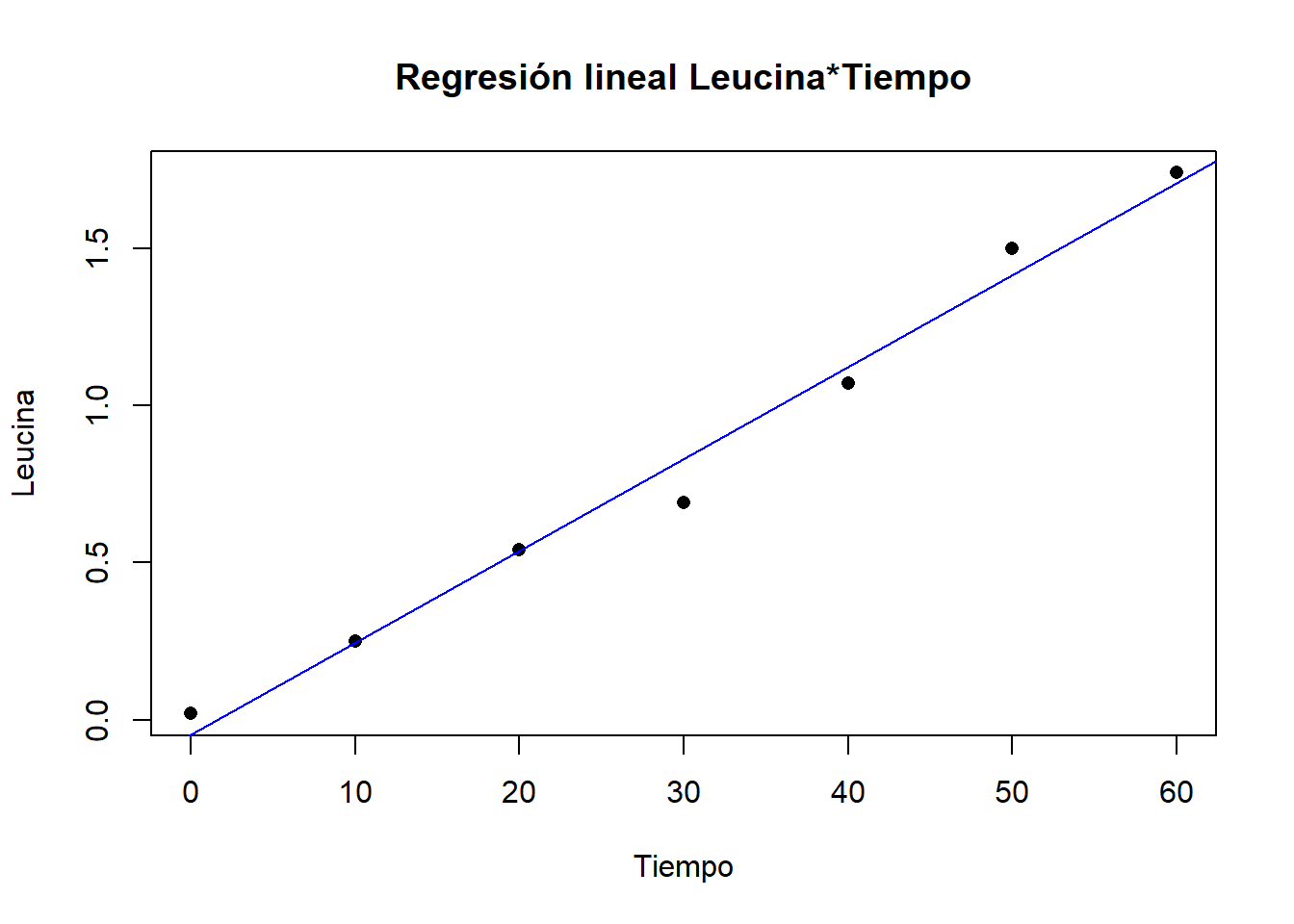
graficamos el modelo
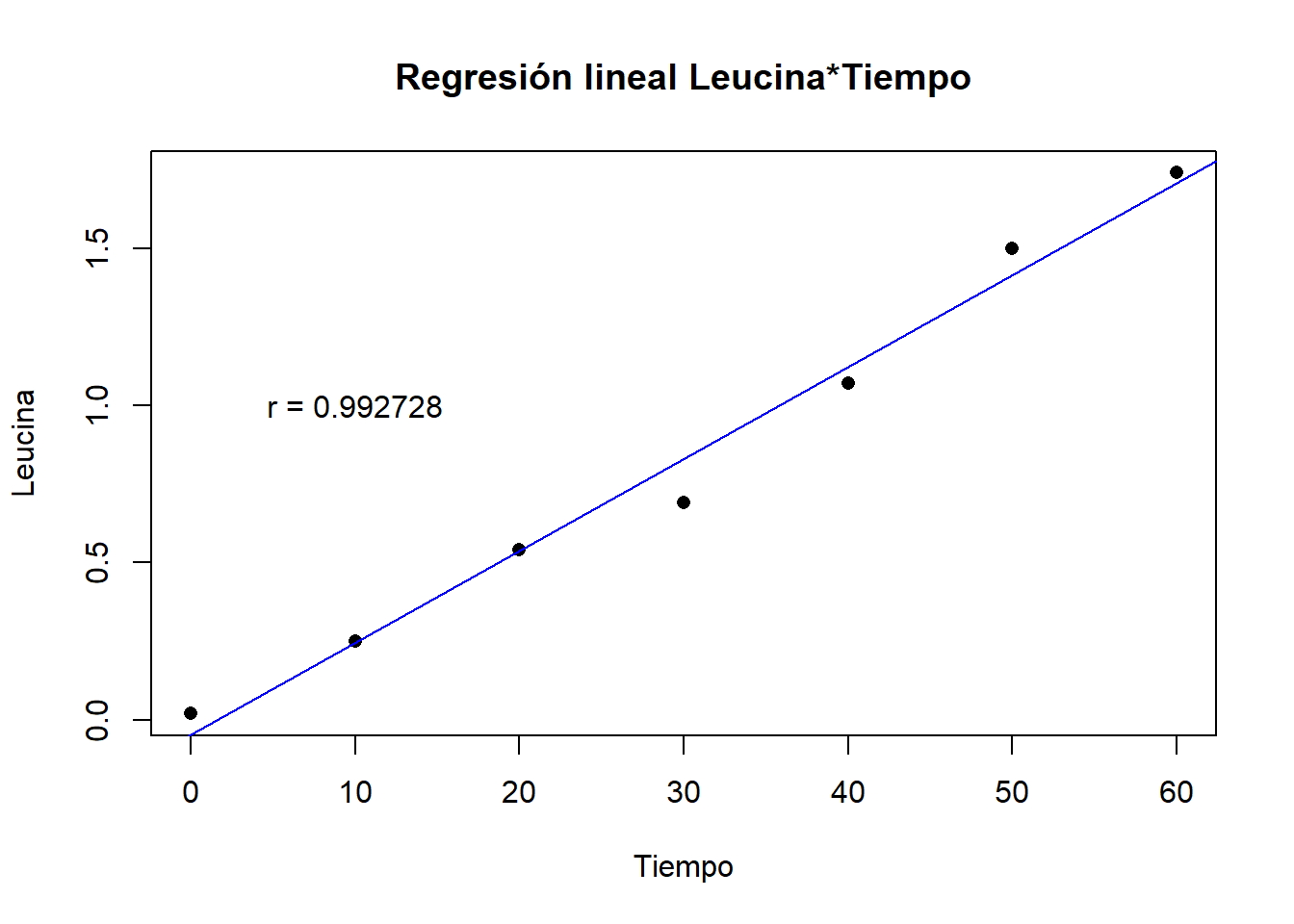
plot(data2$tiempo, data2$leucina, pch=16, xlab ="Tiempo", ylab ="Leucina", main ="Regresión lineal Leucina*Tiempo")abline(modelo2, col ="blue")
Evaluamos mas parámetros con la función summary()
summary(modelo2)
Call:
lm(formula = leucina ~ tiempo, data = data2)
Residuals:
1 2 3 4 5 6 7
0.0675 0.0050 0.0025 -0.1400 -0.0525 0.0850 0.0325
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.047500 0.057192 -0.831 0.444
tiempo 0.029250 0.001586 18.440 8.63e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.08393 on 5 degrees of freedom
Multiple R-squared: 0.9855, Adjusted R-squared: 0.9826
F-statistic: 340 on 1 and 5 DF, p-value: 8.628e-06
los residuos son las diferencias entre los valores observados y los valores predichos por el modelo. Los coeficientes: intercepto es -0.048, y para el tiempo es 0.029, significancia se muestra en la ultima columna. siendo P<0.05. Multiple R-squared: 0.9855, nos indica el coeficiente de determinacion, nos indica cuánta variabilidad en la variable dependiente se explica por las variables independientes.
4.6 Correlación
empleando los datos del ejercicio de regresión:
#manualmente podemos hallar r (coerficiente de correlacion):r <-sum(data2$`(xi-xm)(yi-ym)`)/sqrt(sum(data2$`(xi-xm)^2`)*sum(data2$`(yi-ym)^2`))r
[1] 0.992728
#usando funcion:cor(data2$leucina, data2$tiempo)
[1] 0.992728
#ocor(data2$tiempo, data2$leucina)
[1] 0.992728
grafica: añadimos la correlación
plot(data2$tiempo, data2$leucina, pch=16, xlab ="Tiempo", ylab ="Leucina", main ="Regresión lineal Leucina*Tiempo")abline(modelo2, col ="blue")text(10, 1, "r = 0.992728")